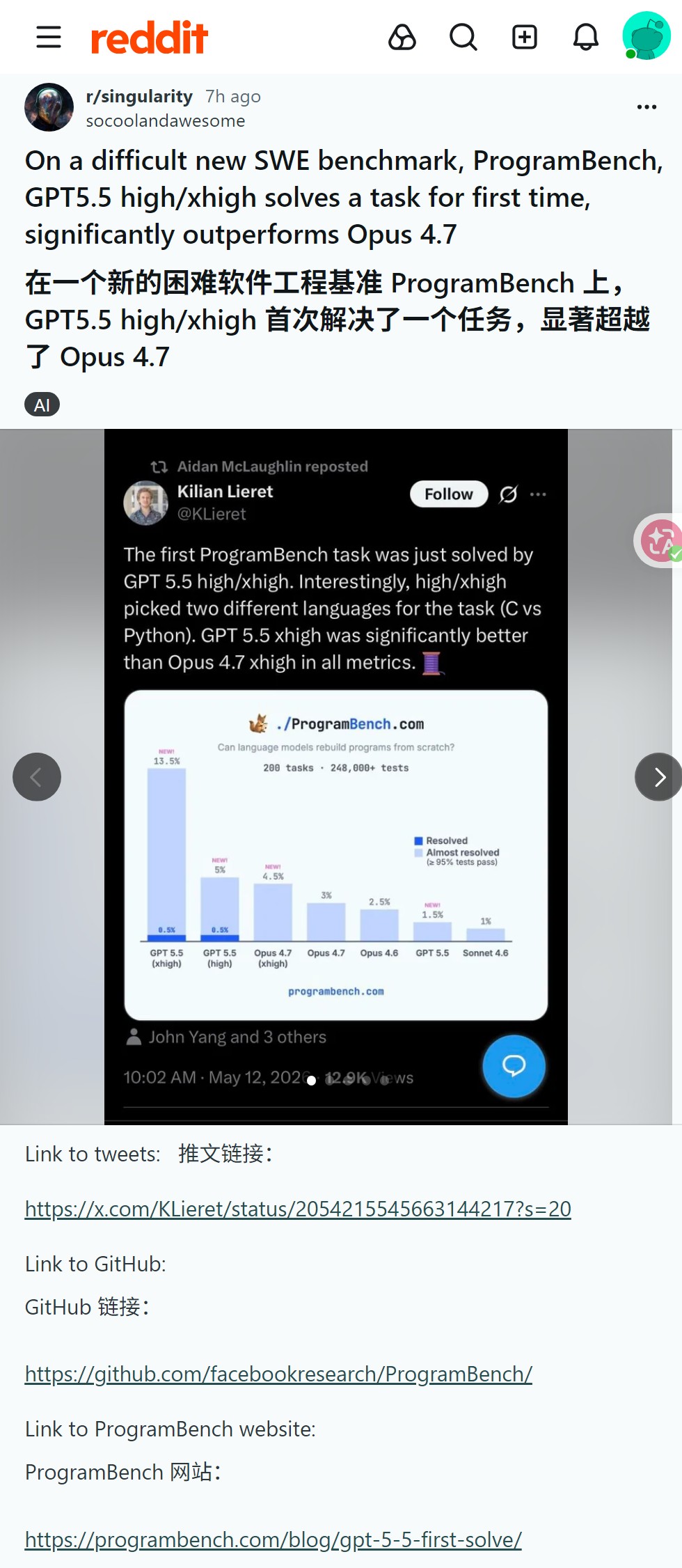
GPT5.5首克新编程基准ProgramBench超Opus4.7,测试合理性遭质疑
2026-05-13 09:13:31
1次阅读
2个评论
帖文称GPT5.5 high/xhigh在全新高难度软件工程基准ProgramBench上首次解决任务,表现显著优于Opus4.7。评论有用户认可其编程表现,也有不少人质疑该基准设计存在缺陷,还讨论了不同档位模型的适用场景。
0
0
 小陈
manage
advert
小陈
manage
advert
2026-05-13 09:14:03

回复 |
引用
小陈
manage
advert
2026-05-13 09:14:32

回复 |
引用
共2条
1
