Reddit热议!Gemma 4模型MTP支持合并,推理速度飙升4倍!
2026-06-08 01:09:32
3次阅读
2个评论
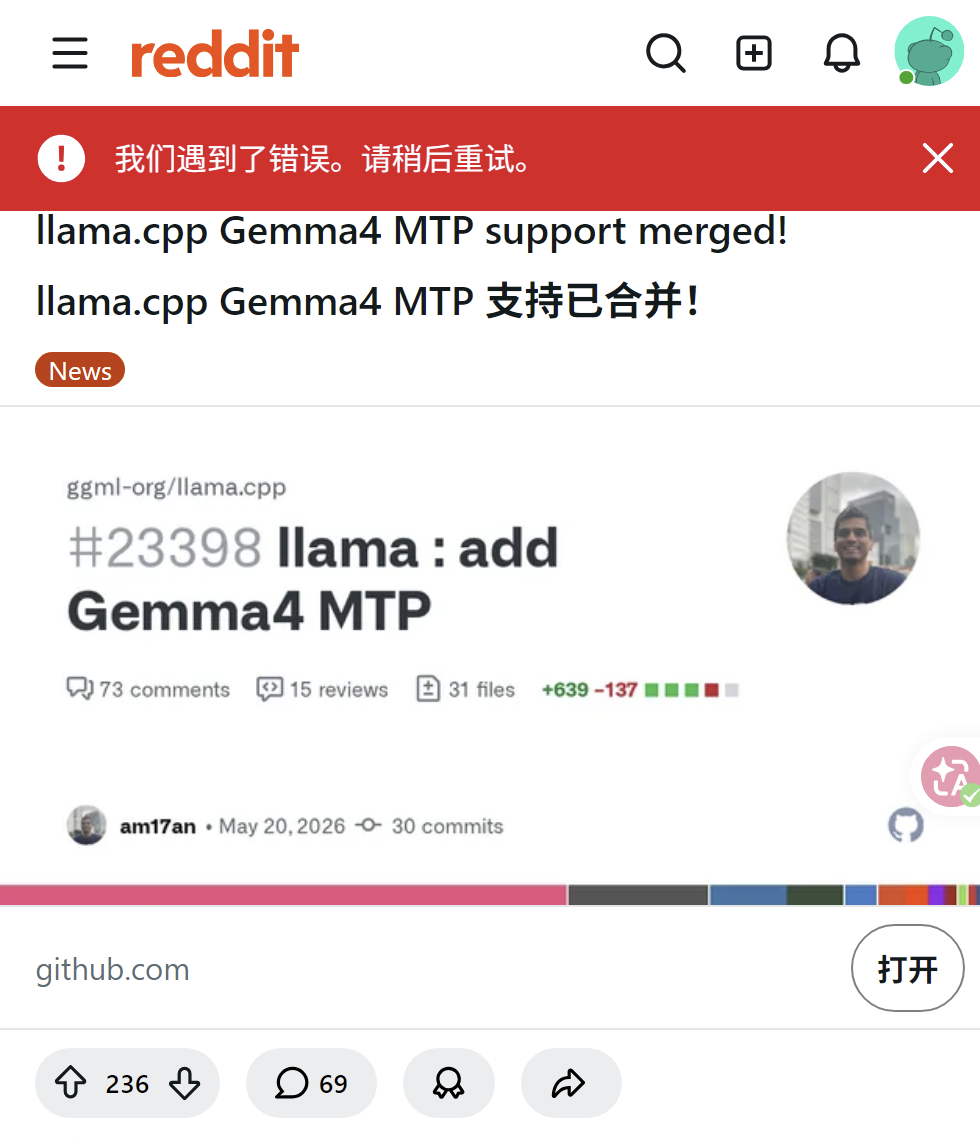
llama.cpp已合并Gemma 4的MTP支持,网友实测在12GB显存上实现140 tok/s,速度提升3-5倍。31B模型在GB10上从6.3 tok/s飙至31.2 tok/s。用户需使用QAT版GGUF与对应MTP草稿模型配合,不可混用版本。开发者感谢社区贡献,认为Gemma 4是全面且实用的模型。
0
0
 小陈
manage
advert
小陈
manage
advert
2026-06-08 01:10:04

回复 |
引用
小陈
manage
advert
2026-06-08 01:10:33

回复 |
引用
共2条
1
