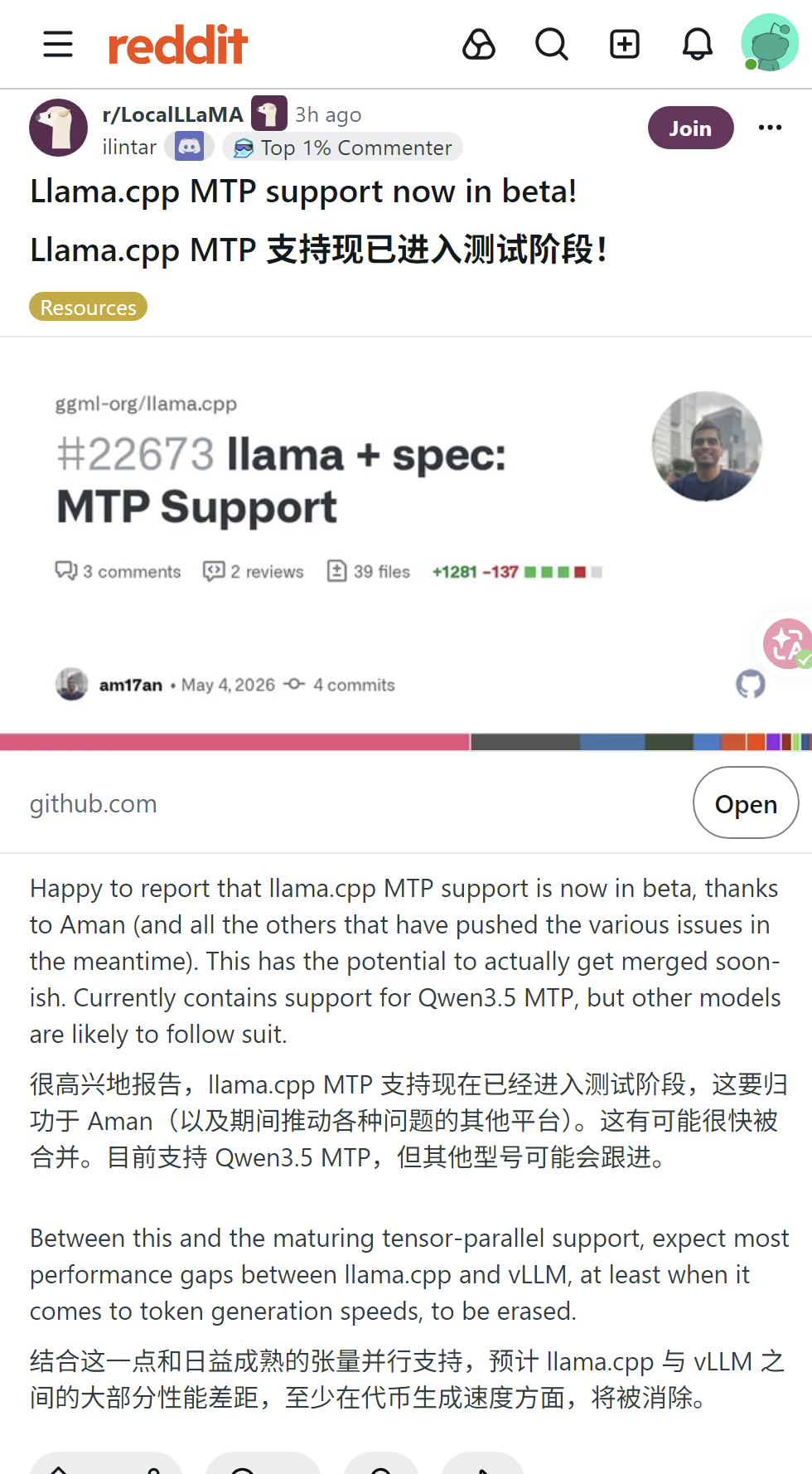
llama.cpp MTP支持进入beta 本地大模型推理大幅提速
2026-05-05 01:47:36
35次阅读
3个评论
本次新增的MTP为内置多令牌预测的自推测解码技术,无需额外草稿模型,有望近期正式合并,目前适配Qwen3.5/3.6系列,稠密模型提速1.5-2倍,MoE提速30-40%,配合张量并行有望追平vLLM,开启后显存增2.7-3.1G,不建议量化MTP层。
0
0
 小陈
manage
advert
小陈
manage
advert
2026-05-05 01:48:09

回复 |
引用
小陈
manage
advert
2026-05-05 01:48:38

回复 |
引用
小陈
manage
advert
2026-05-05 01:49:06

回复 |
引用
共3条
1

相关帖子
- LLaMA.cpp实现MTP功能,Gemma4令牌生成提速40%
- 12GB显存跑Qwen3.6 35B:80tok/s+128K上下文!llama.cpp MTP攻略
- Reddit热议本地大模型:Qwen3.6比肩前沿模型引争议
- ExLlamaV3多项重大更新落地 推理性能猛增引本地LLM社区热议
- 嫁接MTP的Qwen3.6-35B-A3B模型实测结果公布
- Anthropic调整Claude参数被指降质 本地模型价值引热议
- 开发者造出可在iPad本地运行的微型AI世界模型驾驶游戏
- 本地跑Qwen3.6/Gemma4体验佳?网友实测各模型优劣引热议
- 用户用二手英特尔傲腾持久内存攒机 本地跑万亿参数大模型达4token/秒
- 调整Gemma 4视觉令牌参数可大幅提升其视觉识别能力