Reddit热议!DeepSWE新排名:GPT-5.5登顶,Claude Opus 4.8遭质疑
2026-05-31 15:07:23
110次阅读
3个评论
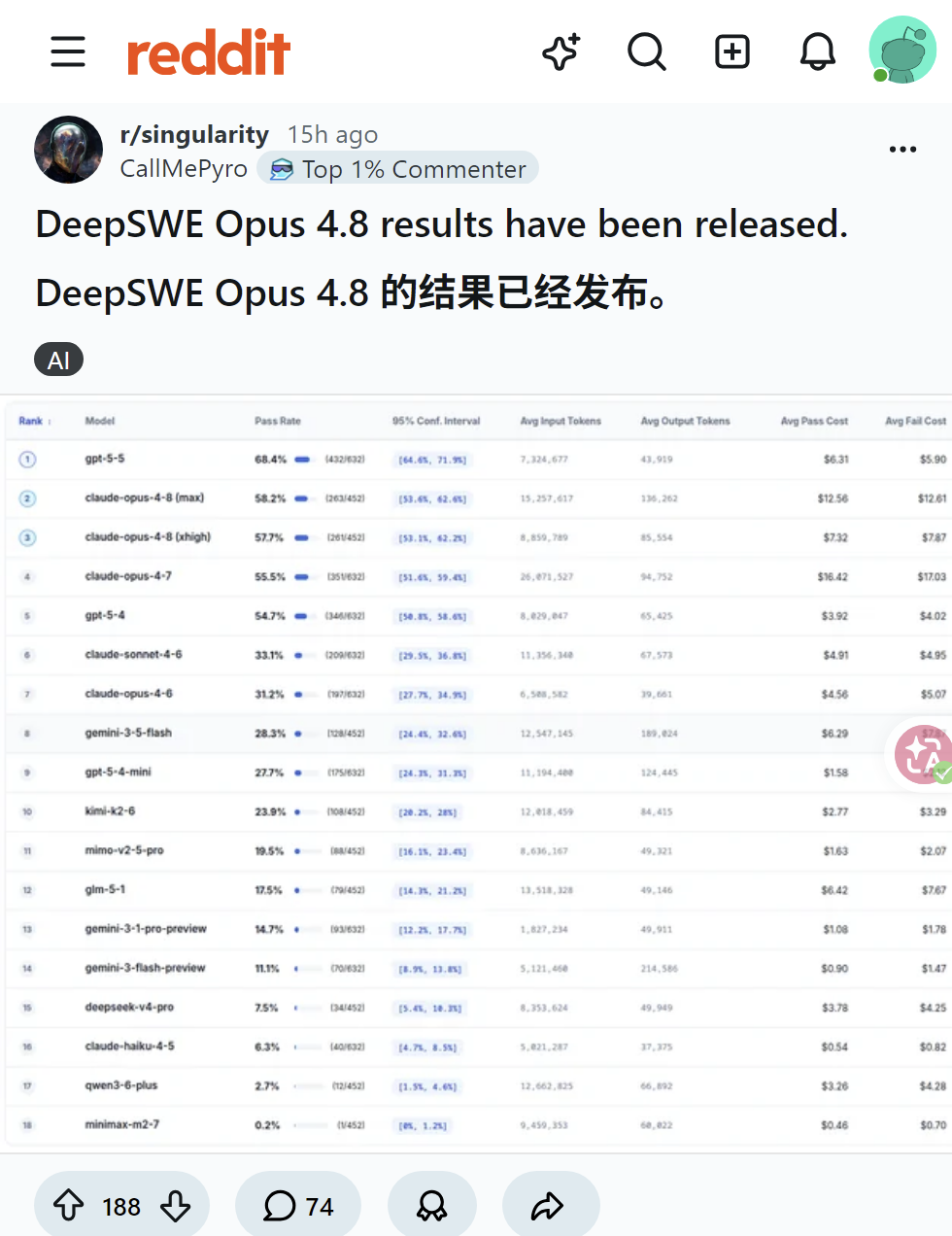
DeepSWE Opus 4.8编程基准测试结果出炉,GPT-5.5表现抢眼引发Reddit网友激烈讨论。多数用户认为Claude模型被过度吹捧且定价过高,实际体验不如GPT-5.5;部分用户指出基准测试可能存在偏颇,因未使用各模型原生测试框架。Anthropic用户抱怨4.8版本在Claude Code中表现糟糕、成本高昂且懒惰,而GPT-5.5在自主性和工具调用方面更胜一筹。网友期待Anthropic即将发布的Mythos能扭转局面。
0
0
 小陈
manage
advert
小陈
manage
advert
2026-05-31 15:07:55

回复 |
引用
小陈
manage
advert
2026-05-31 15:08:24

回复 |
引用
小陈
manage
advert
2026-05-31 15:08:53

回复 |
引用
共3条
1

相关帖子
- GPT-5.5发布引热议:性能提升微弱,定价翻倍遭质疑
- GPT-5.5网安性能优于Mythos,网友质疑Anthropic营销炒作
- Opus4.7登SimpleBench引热议 Gemini高排名遭大量用户质疑
- GPT-5.5基准发布引热议 提升有限未达炒作预期
- Reddit热议!用户吐槽Claude Opus 4.8性能明显下降
- GPT-5.5网攻模拟超Mythos,耗时成本远低于人类专家
- Reddit热议!Claude Opus 4.8频繁“罢工”引发用户强烈不满
- Reddit热议!GPT-5.5自主花150小时改进蛋白质折叠模型,是突破还是过拟合?
- Reddit热帖:菲尔兹奖得主称GPT-5.5可解博士级未解数学题 预警危机引热议
- Reddit热议!Claude 4.8遭用户集体吐槽:废话连篇、烧光额度